
Industry has a pressing need for technology capable of processing AI computations, which have seen more than 300,000 fold increase in just a few years.
Over the last decade or so, AI technology development has advanced and proliferated, leading to new and more complex functionalities, such as image recognition and audio translation. As such, there has been a growing demand for computers capable of performing these kinds of ‘big data processing’ computations.
And we’ve made a lot of progress in a relatively short period of time – the volume of data that could be processed in just 50 seconds in 2018 would’ve taken 15 million seconds (about six months) to process in 2012; that’s a 300,000-fold increase.
However, despite these drastic improvements, computers still aren’t fast enough for many modern processing needs. For example, current GPUs (graphics processing units) take around 10 days to perform machine learning computations on one day's worth of 4K video.
When it comes to tasks that require the examination of large amounts of data, such as video analysis or machine learning, current computers struggle to get it done swiftly.
So to address this issue, Fujitsu has developed a highly efficient method that can boost the rate of parallel distributed computations without sacrificing learning accuracy. This technology managed to beat the previous record-holder for deep-learning processing by 30 seconds, making it the fastest method in the world.
Up until now, computers required sophisticated software technology such as parallelization or special-purpose languages to perform these kinds of computations. As such, the full potential of these computers could only be harnessed by experts with an advanced skillset.
Making computing both fast and user-friendly
Fujitsu Laboratories has achieved a world-first initiative in the development of Content-Aware Computing – ones capable of automatically adjusting the strictness of calculations. These computers can attain high processing speeds but maintain their user-friendliness.
Our laboratories recently developed two new versions of this technology: bit-width reduction and synchronous mitigation.
Bit-width reduction technology: Working to automatically suit your data
Bit-width reduction technology focuses on the progress of deep learning in neural networks and optimizes the bit width in accordance with the distribution of data being processed.
To do this, it first assigns more bits at the early stages of learning when the data has broad distribution. But through the progress of learning, the range of data narrows and it dynamically assigns a narrower bit-width.
So, the technology is constantly striving for the most efficient processing speed, while maintaining the high-quality of its results. We’ve since managed to successfully triple the speed of deep learning using this technology (See Figure 1).
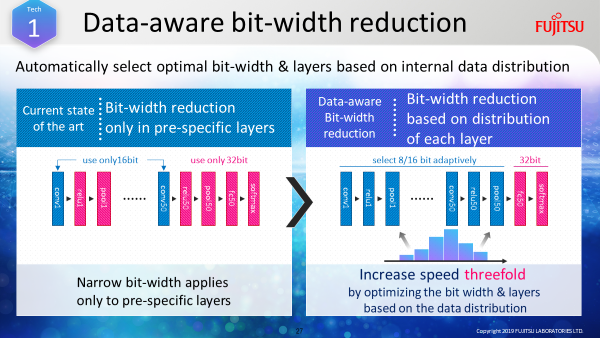
Figure 1: Achieving efficient, fast processing by automatically reducing the bit-width as learning progresses
Synchronous mitigation technology: Enabling processes with different conditions to be executed swiftly in parallel
Synchronous mitigation technology works by examining each calculation being executed in parallel, and automatically adjusts the conditions in order to terminate delayed processes. It makes these decisions by estimating how much time it will take the processes to be synchronized and the potential impact on the results if they were terminated.
For example, conflicts and interruptions can often delay processing response times. This can happen when there’re calculations happening on many nodes at once or when multiple applications are sharing a CPU, creating inefficiencies due to time spent waiting for synchronizations.
Synchronous mitigation technology terminates these processes so it can achieve the shortest execution time and create more stable calculation speeds. We successfully increased the speed of deep learning by 3.7 times through this technology (See Figure 2).
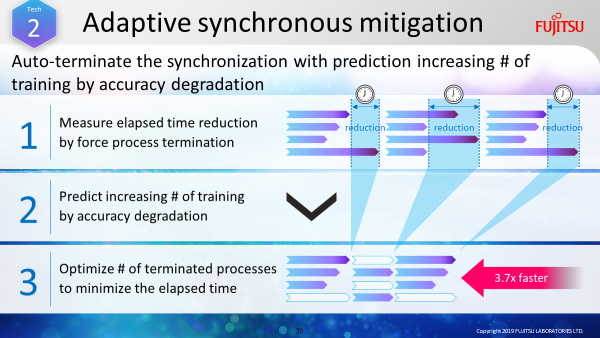
Figure 2: Enabling high-speed calculation by automatically adjusting the termination of processes executed in parallel
These two new types of technology automatically control calculation accuracy to optimally suit the degree of learning, thereby enabling high-speed processing. They also allow for stable calculation speeds in the cloud and other parallelized environments, with varying execution times for each process.
Achieving high-speed, optimized AI processing easily, without the need for expert knowledge
We utilized Content-Aware Computing with deep learning, and by incorporating AI frameworks and libraries, it successfully accelerated AI processing tenfold. This provides benefits for low-bit calculation-ready GPUs and CPUs, as well as cloud offerings and the data centers that use them. As a result, anyone can easily harness the power of this technology without technical knowledge.
Going forward, Fujitsu aims to utilize Content-Aware Computing in more of our DX business offerings by integrating it into more service and platform businesses.










